Mars 2026 Archives
sam. 28 mars 2026 17:39:33 CET
Automatisation d'infrastructure avec Ansible et GitLab CI - Édition 2026
L'année 2026 marque une étape clé dans l'évolution de la série de travaux pratiques consacrée à l'infrastructure en tant que code (IaC). Alors que l'édition 2025 posait les bases de l'automatisation avec des pipelines d'intégration continue, cette nouvelle version se concentre sur l'efficacité opérationnelle, la reproductibilité et l'optimisation des traitements.
Que vous soyez habitué aux systèmes Debian GNU/Linux ou administrateur réseau Cisco IOS XE, ces trois nouveaux supports de TP vous plongent au cœur des pratiques DevOps modernes.
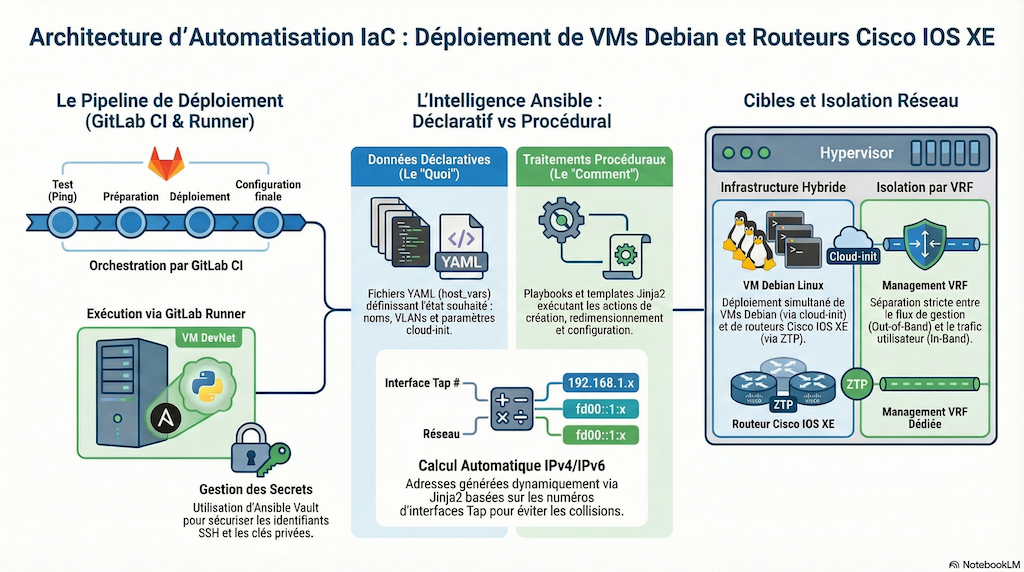
1. Une reproductibilité garantie avec Astral uv
L'une des innovations majeures de cette année est l'adoption du gestionnaire de paquets Astral uv.
-
Rapidité et fiabilité :
Finis les problèmes de versions divergentes entre les environnements de développement et de test. Grâce au fichier pyproject.toml, l'ensemble de la chaîne d'outils Ansible est verrouillé de manière déterministe. -
Intégration CI/CD allégée :
Les pipelines GitLab CI sont simplifiés. Au lieu d'alourdir l'infrastructure avec des images Docker pour exécuter Ansible, nous utilisons une chaîne allégée directement pilotée par uv. Cette approche garantit des traitements idempotents tout en réduisant considérablement le temps de démarrage des tâches (jobs).
2. Des playbooks optimisés et « data-driven »
Le code des playbooks a été entièrement revu. L'objectif ? Une séparation stricte entre les données déclaratives et les procédures d'exécution.
-
Modularité :
Les configurations sont désormais plus lisibles et faciles à maintenir.--- vrouter: vm_name: r2 os: iosxe master_image: "{{ image_name }}" force_copy: false tapnumlist: [6, 7, 8] router_host_id: "{{ vrouter.tapnumlist[0] | int }}" interfaces: - interface_type: GigabitEthernet interface_id: 2 description: --> VLAN 230 enabled: true vlan_id: 230 - interface_type: GigabitEthernet interface_id: 3 description: --> VLAN 800 enabled: true vlan_id: 800 default_routes: "{{ inband_vlans[0].default_routes }}" -
Calcul d'adressage intelligent :
L'utilisation de modules avancés, comme nthost, permet de calculer automatiquement les plans d'adressage IPv4 et IPv6, optimisant ainsi grandement les traitements. Cette approche permet de réduire les erreurs humaines et de déployer rapidement des topologies complexes (VM Linux ou routeurs IOS XE), en modifiant simplement une variable de groupe.--- inband_vlans: - vlan: 230 subnet4: 10.0.228.0/22 subnet6: 2001:db8:e6::/64 default_routes: ipv4_next_hop: 10.0.228.1 ipv6_next_hop: 2001:db8:e6::1 - vlan: 800 subnet6: 2001:db8:320::/64
3. Gestion des secrets : trouver l'équilibre entre sécurité et simplicité
Cette édition maintient volontairement une « entorse » aux bonnes pratiques académiques concernant la gestion des secrets pour cette édition.
-
Simplification pédagogique :
Plutôt que d'introduire un coffre-fort numérique tiers (type HashiCorp Vault), nous conservons l'usage d'Ansible Vault. -
Le coût du partage :
Ce choix engendre toutefois un coût opérationnel, car les secrets doivent être partagés entre le compte du développeur et celui du GitLab Runner. En revanche, il permet de se concentrer sur l'essentiel, c'est-à-dire la logique de déploiement de l'infrastructure, sans multiplier les dépendances logicielles.
4. Pourquoi étudier ces supports ?
Que vous souhaitiez construire des machines Debian à partir d'images cloud ou orchestrer des routeurs virtuels via des pipelines CI/CD complets, cette série 2026 vous permettra d'apprendre à passer d'une administration manuelle à une gestion d'infrastructure entièrement automatisée.
Prêt à automatiser ? Découvrez les trois volets de la série :
Posté par Philippe Latu | permalien | dans : m2, formations, iac, travaux_pratiques, système, virtualisation | Read it in english with Google
dim. 08 mars 2026 17:03:53 CET
Renforcez la protection de votre serveur avec le fork Python de nft-blacklist
Après avoir enfin réussi à migrer d’iptables vers nftables sur les machines que j’exploite, j’ai utilisé pendant plusieurs mois le script shell nft-blacklist tel qu’il est proposé à l’adresse https://github.com/leshniak/nft-blacklist.
Récemment, ce script a commencé à produire des erreurs sur l’une de mes passerelles sous Debian testing. Plutôt que de corriger les expressions rationnelles et de multiplier les outils tiers, j’ai choisi de m’appuyer sur le module standard ipaddress de Python pour manipuler proprement adresses et réseaux IPv4/IPv6.
Après quelques heures de travail assisté par l’IA, j’ai le plaisir de vous présenter un fork en Python, entièrement réécrit et optimisé, de l’outil nft-blacklist. Ce code a pour objectif de gérer rapidement et de manière robuste des listes noires de grande taille d’adresses IP pour un pare-feu basé sur nftables.
Pourquoi un fork ? Genèse de la réécriture
Avec la multiplication des tentatives d’attaques automatisées, des outils comme fail2ban utilisés seuls ne suffisent plus. Il devient nécessaire de mieux contrôler les performances et l’utilisation des ressources sur les serveurs exposés à Internet (VPS, passerelles, serveurs d’applications, etc.).
C’est dans ce contexte que j’ai réécrit l’intégralité du script en Python 3, en m’appuyant sur un fichier de configuration au format TOML. L’objectif est triple : améliorer les performances, renforcer la robustesse et rendre le code plus simple à maintenir.
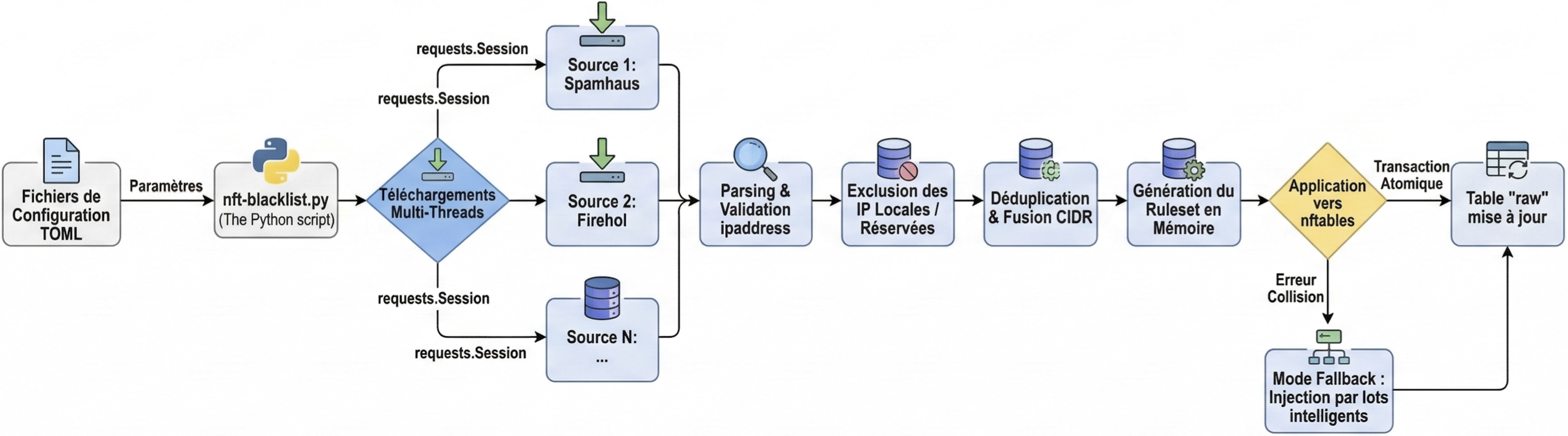
Voici le workflow synthétique du nouveau script :
Principales optimisations du fork Python
Le fork, disponible à l’adresse https://github.com/platu/nft-blacklist, se distingue par plusieurs optimisations clés par rapport au script shell initial.
1. Parallélisation des téléchargements
Script shell initial : les listes de sources sont téléchargées séquentiellement, l’une après l’autre. Si une seule source est lente, tout le processus est ralenti.
Fork Python : grâce au module concurrent.futures, le script télécharge toutes les listes noires en parallèle. L’utilisation d’une unique requests.Session() permet en outre de réutiliser les connexions TCP/TLS (connection pooling), ce qui réduit fortement le temps passé en I/O réseau, surtout avec de longues listes. On peut ainsi obtenir un gain de performance de l’ordre de 10x à 50x sur cette phase.
2. Validation robuste des adresses
Script shell initial : l’analyse repose sur des expressions régulières et des outils comme awk ou grep, sensibles aux variations de format des fichiers. La validation des adresses IP reste assez basique.
Fork Python : le module standard ipaddress assure une analyse et une validation strictes. Chaque ligne est interprétée comme adresse ou réseau IPv4/IPv6, et seules les entrées valides sont conservées. Les lignes vides et les commentaires sont filtrés proprement, ce qui évite les mauvaises surprises.
3. Consolidation et déduplication des listes
Script shell initial : les doublons sont généralement éliminés via un simple sort | uniq. Il n’y a pas de consolidation native des réseaux (par exemple fusionner 1.2.3.0/24 et 1.2.3.4/32 qui se chevauchent).
Fork Python : le script déduplique instantanément toutes les adresses à l’aide d’un set() Python performant. Surtout, il utilise ipaddress.collapse_addresses() pour fusionner et consolider les réseaux redondants. Le résultat est un jeu de règles nftables beaucoup plus compact, qui consomme moins de mémoire et réduit le nombre de comparaisons effectuées par le pare-feu.
4. Application atomique et rapidité
Script shell initial : beaucoup de scripts shell appliquent les règles élément par élément, ou génèrent de multiples fichiers temporaires. En cas d’erreur de type File exists, ils basculent dans un mode de secours (fallback) souvent très lent.
Fork Python : le script génère en mémoire (via stdin) un fichier de configuration complet et optimisé, puis l’applique en une seule transaction atomique avec la commande nft -f. En cas de succès, la mise à jour du pare-feu est instantanée et cohérente. En cas d’erreur, l’état précédent est préservé. Le mode de secours a été réécrit pour ne traiter que les blocs défaillants, faisant passer cette phase de plusieurs minutes à quelques secondes.
5. Code propre, typage et journalisation
Script shell initial : un script shell qui grossit peut rapidement devenir difficile à lire et à faire évoluer, avec des lignes mêlant sed, awk et substitutions diverses.
Fork Python : le code est écrit en Python typé (type hints) afin de faciliter la relecture et la détection d’erreurs. Il s’appuie sur le module standard logging pour s’intégrer proprement avec le journal système et offrir un diagnostic clair en cas de problème.
Prérequis et intégration
Le script cible principalement les environnements GNU/Linux disposant de nftables (par exemple Debian/Ubuntu récentes) et d’un Python 3 à jour. Un exemple de fichier de configuration TOML est fourni dans le dépôt Git, afin de faciliter l’intégration avec votre propre jeu de règles.
Conclusion
Ce fork Python de nft-blacklist constitue une évolution importante du projet initial. Il est plus rapide, plus robuste et génère des règles nftables nettement plus optimisées, ce qui contribue à préserver les ressources de votre serveur tout en améliorant votre surface de défense.
N’hésitez pas à tester ce nouvel outil et à me faire part de vos retours sur le dépôt GitHub : https://github.com/platu/nft-blacklist.