sam. 28 mars 2026 17:39:33 CET
Automatisation d'infrastructure avec Ansible et GitLab CI - Édition 2026
L'année 2026 marque une étape clé dans l'évolution de la série de travaux pratiques consacrée à l'infrastructure en tant que code (IaC). Alors que l'édition 2025 posait les bases de l'automatisation avec des pipelines d'intégration continue, cette nouvelle version se concentre sur l'efficacité opérationnelle, la reproductibilité et l'optimisation des traitements.
Que vous soyez habitué aux systèmes Debian GNU/Linux ou administrateur réseau Cisco IOS XE, ces trois nouveaux supports de TP vous plongent au cœur des pratiques DevOps modernes.
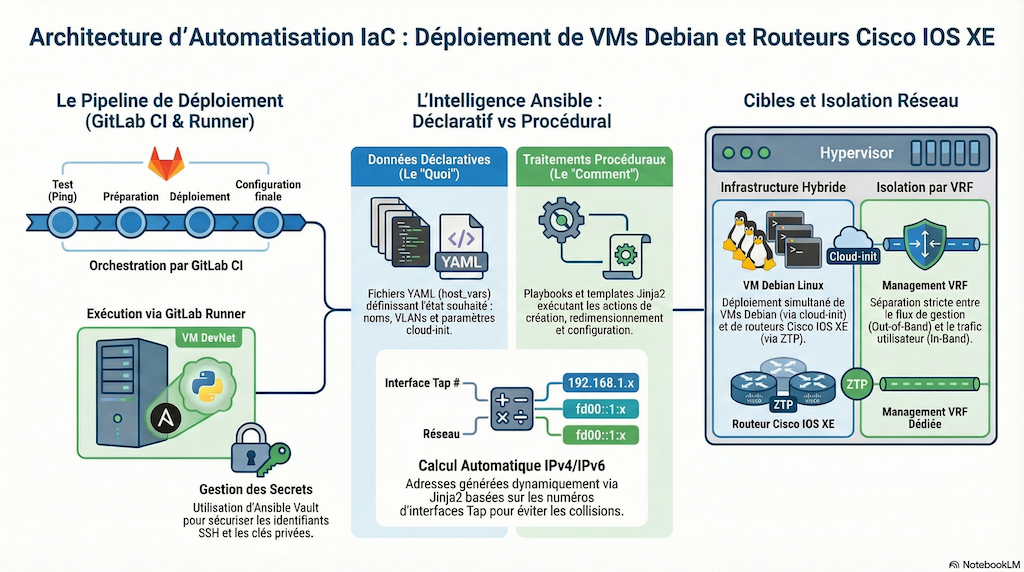
1. Une reproductibilité garantie avec Astral uv
L'une des innovations majeures de cette année est l'adoption du gestionnaire de paquets Astral uv.
-
Rapidité et fiabilité :
Finis les problèmes de versions divergentes entre les environnements de développement et de test. Grâce au fichier pyproject.toml, l'ensemble de la chaîne d'outils Ansible est verrouillé de manière déterministe. -
Intégration CI/CD allégée :
Les pipelines GitLab CI sont simplifiés. Au lieu d'alourdir l'infrastructure avec des images Docker pour exécuter Ansible, nous utilisons une chaîne allégée directement pilotée par uv. Cette approche garantit des traitements idempotents tout en réduisant considérablement le temps de démarrage des tâches (jobs).
2. Des playbooks optimisés et « data-driven »
Le code des playbooks a été entièrement revu. L'objectif ? Une séparation stricte entre les données déclaratives et les procédures d'exécution.
-
Modularité :
Les configurations sont désormais plus lisibles et faciles à maintenir.--- vrouter: vm_name: r2 os: iosxe master_image: "{{ image_name }}" force_copy: false tapnumlist: [6, 7, 8] router_host_id: "{{ vrouter.tapnumlist[0] | int }}" interfaces: - interface_type: GigabitEthernet interface_id: 2 description: --> VLAN 230 enabled: true vlan_id: 230 - interface_type: GigabitEthernet interface_id: 3 description: --> VLAN 800 enabled: true vlan_id: 800 default_routes: "{{ inband_vlans[0].default_routes }}" -
Calcul d'adressage intelligent :
L'utilisation de modules avancés, comme nthost, permet de calculer automatiquement les plans d'adressage IPv4 et IPv6, optimisant ainsi grandement les traitements. Cette approche permet de réduire les erreurs humaines et de déployer rapidement des topologies complexes (VM Linux ou routeurs IOS XE), en modifiant simplement une variable de groupe.--- inband_vlans: - vlan: 230 subnet4: 10.0.228.0/22 subnet6: 2001:db8:e6::/64 default_routes: ipv4_next_hop: 10.0.228.1 ipv6_next_hop: 2001:db8:e6::1 - vlan: 800 subnet6: 2001:db8:320::/64
3. Gestion des secrets : trouver l'équilibre entre sécurité et simplicité
Cette édition maintient volontairement une « entorse » aux bonnes pratiques académiques concernant la gestion des secrets pour cette édition.
-
Simplification pédagogique :
Plutôt que d'introduire un coffre-fort numérique tiers (type HashiCorp Vault), nous conservons l'usage d'Ansible Vault. -
Le coût du partage :
Ce choix engendre toutefois un coût opérationnel, car les secrets doivent être partagés entre le compte du développeur et celui du GitLab Runner. En revanche, il permet de se concentrer sur l'essentiel, c'est-à-dire la logique de déploiement de l'infrastructure, sans multiplier les dépendances logicielles.
4. Pourquoi étudier ces supports ?
Que vous souhaitiez construire des machines Debian à partir d'images cloud ou orchestrer des routeurs virtuels via des pipelines CI/CD complets, cette série 2026 vous permettra d'apprendre à passer d'une administration manuelle à une gestion d'infrastructure entièrement automatisée.
Prêt à automatiser ? Découvrez les trois volets de la série :
dim. 08 mars 2026 17:03:53 CET
Renforcez la protection de votre serveur avec le fork Python de nft-blacklist
Après avoir enfin réussi à migrer d’iptables vers nftables sur les machines que j’exploite, j’ai utilisé pendant plusieurs mois le script shell nft-blacklist tel qu’il est proposé à l’adresse https://github.com/leshniak/nft-blacklist.
Récemment, ce script a commencé à produire des erreurs sur l’une de mes passerelles sous Debian testing. Plutôt que de corriger les expressions rationnelles et de multiplier les outils tiers, j’ai choisi de m’appuyer sur le module standard ipaddress de Python pour manipuler proprement adresses et réseaux IPv4/IPv6.
Après quelques heures de travail assisté par l’IA, j’ai le plaisir de vous présenter un fork en Python, entièrement réécrit et optimisé, de l’outil nft-blacklist. Ce code a pour objectif de gérer rapidement et de manière robuste des listes noires de grande taille d’adresses IP pour un pare-feu basé sur nftables.
Pourquoi un fork ? Genèse de la réécriture
Avec la multiplication des tentatives d’attaques automatisées, des outils comme fail2ban utilisés seuls ne suffisent plus. Il devient nécessaire de mieux contrôler les performances et l’utilisation des ressources sur les serveurs exposés à Internet (VPS, passerelles, serveurs d’applications, etc.).
C’est dans ce contexte que j’ai réécrit l’intégralité du script en Python 3, en m’appuyant sur un fichier de configuration au format TOML. L’objectif est triple : améliorer les performances, renforcer la robustesse et rendre le code plus simple à maintenir.
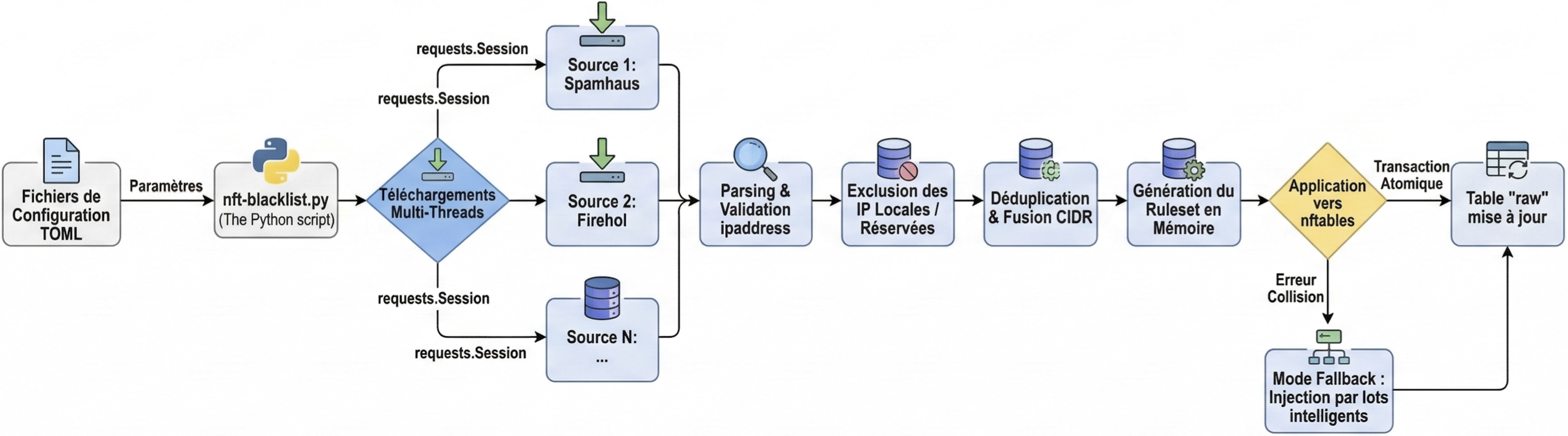
Voici le workflow synthétique du nouveau script :
Principales optimisations du fork Python
Le fork, disponible à l’adresse https://github.com/platu/nft-blacklist, se distingue par plusieurs optimisations clés par rapport au script shell initial.
1. Parallélisation des téléchargements
Script shell initial : les listes de sources sont téléchargées séquentiellement, l’une après l’autre. Si une seule source est lente, tout le processus est ralenti.
Fork Python : grâce au module concurrent.futures, le script télécharge toutes les listes noires en parallèle. L’utilisation d’une unique requests.Session() permet en outre de réutiliser les connexions TCP/TLS (connection pooling), ce qui réduit fortement le temps passé en I/O réseau, surtout avec de longues listes. On peut ainsi obtenir un gain de performance de l’ordre de 10x à 50x sur cette phase.
2. Validation robuste des adresses
Script shell initial : l’analyse repose sur des expressions régulières et des outils comme awk ou grep, sensibles aux variations de format des fichiers. La validation des adresses IP reste assez basique.
Fork Python : le module standard ipaddress assure une analyse et une validation strictes. Chaque ligne est interprétée comme adresse ou réseau IPv4/IPv6, et seules les entrées valides sont conservées. Les lignes vides et les commentaires sont filtrés proprement, ce qui évite les mauvaises surprises.
3. Consolidation et déduplication des listes
Script shell initial : les doublons sont généralement éliminés via un simple sort | uniq. Il n’y a pas de consolidation native des réseaux (par exemple fusionner 1.2.3.0/24 et 1.2.3.4/32 qui se chevauchent).
Fork Python : le script déduplique instantanément toutes les adresses à l’aide d’un set() Python performant. Surtout, il utilise ipaddress.collapse_addresses() pour fusionner et consolider les réseaux redondants. Le résultat est un jeu de règles nftables beaucoup plus compact, qui consomme moins de mémoire et réduit le nombre de comparaisons effectuées par le pare-feu.
4. Application atomique et rapidité
Script shell initial : beaucoup de scripts shell appliquent les règles élément par élément, ou génèrent de multiples fichiers temporaires. En cas d’erreur de type File exists, ils basculent dans un mode de secours (fallback) souvent très lent.
Fork Python : le script génère en mémoire (via stdin) un fichier de configuration complet et optimisé, puis l’applique en une seule transaction atomique avec la commande nft -f. En cas de succès, la mise à jour du pare-feu est instantanée et cohérente. En cas d’erreur, l’état précédent est préservé. Le mode de secours a été réécrit pour ne traiter que les blocs défaillants, faisant passer cette phase de plusieurs minutes à quelques secondes.
5. Code propre, typage et journalisation
Script shell initial : un script shell qui grossit peut rapidement devenir difficile à lire et à faire évoluer, avec des lignes mêlant sed, awk et substitutions diverses.
Fork Python : le code est écrit en Python typé (type hints) afin de faciliter la relecture et la détection d’erreurs. Il s’appuie sur le module standard logging pour s’intégrer proprement avec le journal système et offrir un diagnostic clair en cas de problème.
Prérequis et intégration
Le script cible principalement les environnements GNU/Linux disposant de nftables (par exemple Debian/Ubuntu récentes) et d’un Python 3 à jour. Un exemple de fichier de configuration TOML est fourni dans le dépôt Git, afin de faciliter l’intégration avec votre propre jeu de règles.
Conclusion
Ce fork Python de nft-blacklist constitue une évolution importante du projet initial. Il est plus rapide, plus robuste et génère des règles nftables nettement plus optimisées, ce qui contribue à préserver les ressources de votre serveur tout en améliorant votre surface de défense.
N’hésitez pas à tester ce nouvel outil et à me faire part de vos retours sur le dépôt GitHub : https://github.com/platu/nft-blacklist.
lun. 12 janv. 2026 17:42:40 CET
Enseignements Ops à l'ère du déclaratif : entre progrès et dérives
En bref :
- L'adoption de pratiques déclaratives (YAML, Cloud-init, Incus) améliore considérablement la reproductibilité des travaux pratiques, mais crée un fossé entre les étudiants qui structurent leur démarche et ceux qui se contentent de copier-coller des configurations.
- L'utilisation non contextualisée de l'IA, comme ChatGPT, conduit certains étudiants à exécuter des commandes incohérentes et déconnectées des énoncés.
- Dans une logique inspirée de DevOps, les évaluations doivent exiger le contexte complet d'exécution (environnements, déclarations, artefacts de preuve) ainsi que des méthodes de sélection et de validation des sources.
Après avoir migré la gestion des machines virtuelles vers le mode déclaratif basé sur des fichiers YAML (voir le code du script lab-startup.py), j'ai ajouté l'utilisation de Cloud-init en septembre dernier.
La dernière révision du support de travaux pratiques intitulé « Start unprivileged Incus containers on top of Open vSwitch in a few steps » illustre bien cette évolution. Les premières parties proposent de réaliser les opérations de mise en place de la topologie ci-dessous une à une, tandis que la dernière partie les réalise en mode déclaratif.

Les travaux pratiques ont beaucoup gagné en reproductibilité. Cette évolution met toutefois en lumière un écart croissant entre les étudiants qui structurent mieux le développement des déclarations et ceux qui se contentent de copier-coller des configurations sans comprendre les opérations d'administration système attendues.
Le paradoxe de l'abstraction déclarative
Cette approche marque une rupture avec les pratiques impératives classiques. Auparavant, chaque commande était exécutée en observant son effet ; aujourd'hui, les fichiers YAML décrivent un état attendu sans détailler les étapes. Cette abstraction constitue un véritable progrès pour l'industrialisation et la reproductibilité.
Sur le plan pédagogique, elle crée toutefois un piège. Les étudiants les plus investis l'utilisent pour mieux structurer le séquencement des opérations. D'autres, en revanche, utilisent les salons Discord comme des « marketplaces YAML » et récupèrent des configurations toutes faites, au détriment de l'objectif central, à savoir analyser un problème, choisir les actions nécessaires et construire une solution cohérente.
L'IA conversationnelle : un faux ami pédagogique !
L'utilisation d'agents conversationnels tels que ChatGPT amplifie cette dérive. L'analyse des logs des hyperviseurs révèle des tentatives d'exécution de commandes incohérentes, totalement déconnectées des énoncés des travaux pratiques. Le problème n'est pas que les étudiants commettent des erreurs — l'erreur fait pleinement partie du processus d'apprentissage —, mais qu'ils exécutent des instructions sans rapport avec le contexte pédagogique, ce qui témoigne d'une absence totale d'attention et de réflexion.
Au lieu de l'utiliser comme assistant pour approfondir leur compréhension, quelques étudiants sollicitent l'IA sans la moindre contextualisation. Ils obtiennent ainsi des réponses génériques (j'aurais envie d'écrire « hallucinées ») qui ne correspondent ni à l'environnement de formation ni aux objectifs pédagogiques. L'IA devient alors un obstacle à l'apprentissage.
Le contexte de la formation initiale ne facilite pas les choses
Les ressources documentaires sont largement accessibles en ligne, et les solutions aux exercices pratiques sont disponibles publiquement. Cette accessibilité, combinée à la facilité d'interroger des agents conversationnels, supprime toute incitation à fournir un effort de contextualisation et de sélection précise des sources.
Il est donc nécessaire d'insister davantage sur deux points : la sélection des documents et la validation de l'applicabilité des réponses, notamment via des méthodologies telles que la génération augmentée par recherche (RAG), qui ancrent l'IA dans un corpus précis. C'est un axe de progression identifié pour les prochains modules.
Je sais depuis longtemps que l'enseignement des opérations doit privilégier des évaluations en conditions réelles, avec un temps limité. En revanche, je suis beaucoup plus sceptique quant au recours systématique au dépannage de systèmes volontairement altérés. En effet, la restitution basée sur la justification des choix techniques et la résolution de problèmes peut être réalisée en totalité par une IA.
Affaire à suivre...
Dans le prolongement du paradigme DevOps, le code produit par les étudiants dans le cadre d'un projet de développement doit désormais être livré avec son contexte d'exécution complet (environnements virtuels Python, dépendances et paramètres). La restitution des opérations d'administration système doit quant à elle inclure les éléments de preuve (artéfacts) permettant de générer des tests unitaires, ainsi que les sources déclaratives ayant conduit aux résultats observés. Jusqu'à présent, je demande aux étudiants de fournir un compte rendu des résultats importants au format Markdown sur un canal Mattermost. Il faut faire évoluer cette pratique. Affaire à suivre donc.
lun. 06 oct. 2025 09:13:51 CEST
Introduction au système de fichiers réseau NFSv4 - édition 2025
NFS fête ses 40 ans
Le protocole NFS (Network File System) vient de célébrer son 40e anniversaire ! Depuis 1984, il a profondément transformé l'accès aux fichiers en réseau. Il est devenu incontournable pour tous les administrateurs de systèmes Unix et Linux. À cette occasion, le support de travaux pratiques « Introduction au système de fichiers réseau NFSv4 » a été entièrement révisé et enrichi pour répondre aux enjeux de la sécurité et de l'administration moderne.
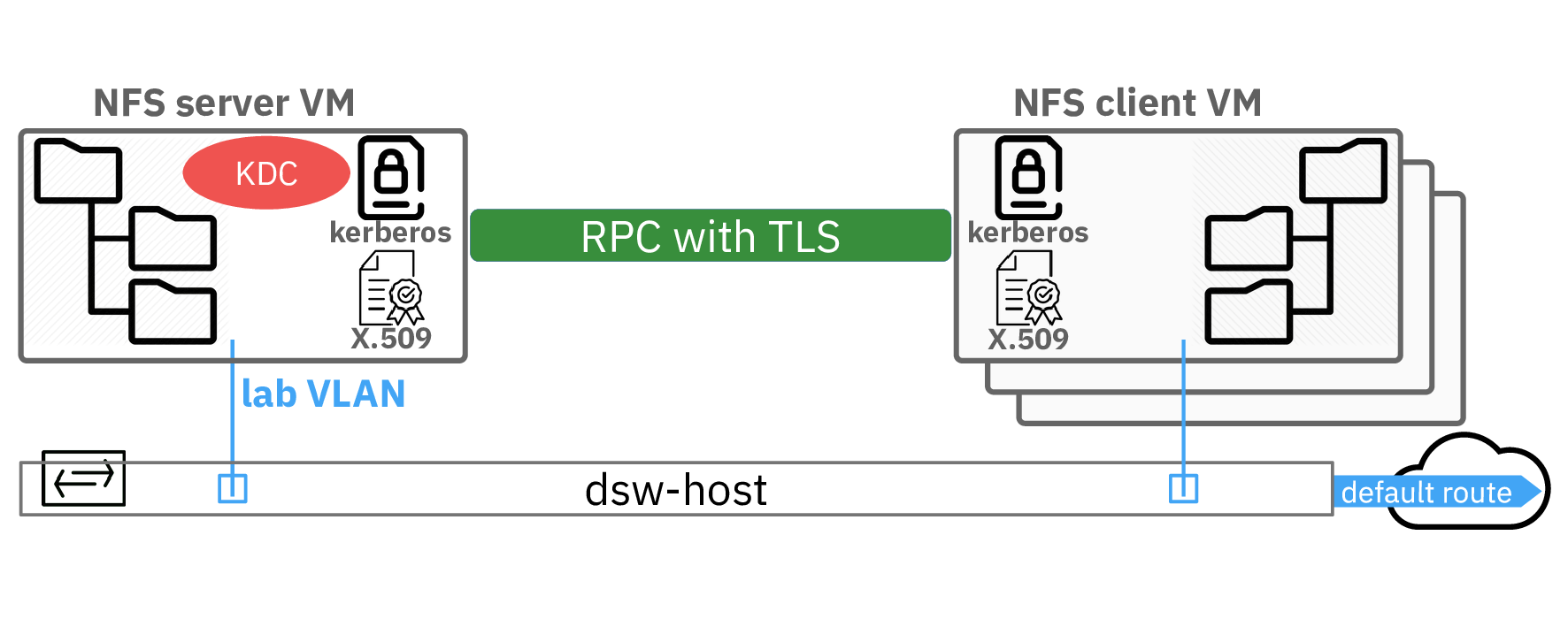
Un support pédagogique complet, pensé pour la pratique
Ce document propose une exploration progressive du protocole NFSv4, des bases des appels RPC aux montages dynamiques sous Linux. Le plan guide pas à pas à travers les étapes suivantes :
- l'identification et la configuration des services réseau historiques, tels que rpcbind et portmapper ;
- la mise en place d'une maquette minimaliste de type NAS avec exportation d'arborescences et création de comptes utilisateurs locaux ;
- le paramétrage des montages manuels et automatisés via autofs ;
- le contrôle des permissions et de la cohérence des identités locales et distantes, à l'aide de tests sur différentes valeurs UID/GID.
Nouveauté 2025 : la sécurité avancée NFS, de bout en bout
Le cœur de cette nouvelle édition réside dans une nouvelle section consacrée à la sécurité. Avec l’adoption croissante de NFS dans des contextes sensibles (cloud, intelligence artificielle, clusters scientifiques), la sécurisation n’est plus une option.
- La configuration de Kerberos V5 est désormais détaillée pour permettre une authentification stricte des identités avec la gestion des éléments principaux (realm, keytab, etc.).
- Le chiffrement TLS sur RPC (RFC 9289) : le guide explique comment activer le chiffrement de bout en bout avec TLS grâce au démon tlshd, offrant ainsi une protection contre les interceptions de trafic réseau.
- Les étapes de déploiement intégrées sont décrites, de la génération des identités et des certificats à la configuration sur le client et le serveur, allant jusqu'à la validation des communications.
Vous apprendrez à capturer et à analyser le trafic réseau afin de distinguer un flux NFS en clair d'un flux protégé par Kerberos et TLS, ainsi qu'à vérifier pas à pas l'authentification dans les journaux Kerberos.
Enfin, la conclusion ouvre la voie au prochain défi incontournable : la gestion centralisée des identités via un annuaire LDAP – indispensable pour industrialiser NFS dans les grandes infrastructures.
Pour développer vos compétences et découvrir NFS comme vous ne l'avez jamais administré, (re)découvrez ce support de travaux pratiques, un classique renouvelé à l'image des 40 ans d'innovation du protocole NFS !
Le support « Introduction au système de fichiers réseau NFSv4 » est disponible en version PDF.
Relevez le défi ! L'association Kerberos et TLS permet de décentraliser le stockage tout en le rapprochant de l'utilisateur, sans compromettre la protection des données.
lun. 01 sept. 2025 15:08:41 CEST
Administration Système et Réseaux : l'écosystème du stockage et de l'identité numérique
Alors que s'ouvre une nouvelle année universitaire, les étudiants de première année de master Réseaux et Télécommunications de l'université de Toulouse sont confrontés à des défis technologiques majeurs : maîtriser l'évolution toujours plus rapide des architectures de stockage et les enjeux cruciaux de la gestion de l'identité numérique.
Voici une brève introduction aux trois supports de cours utilisés dans le module Administration Système et Réseaux.
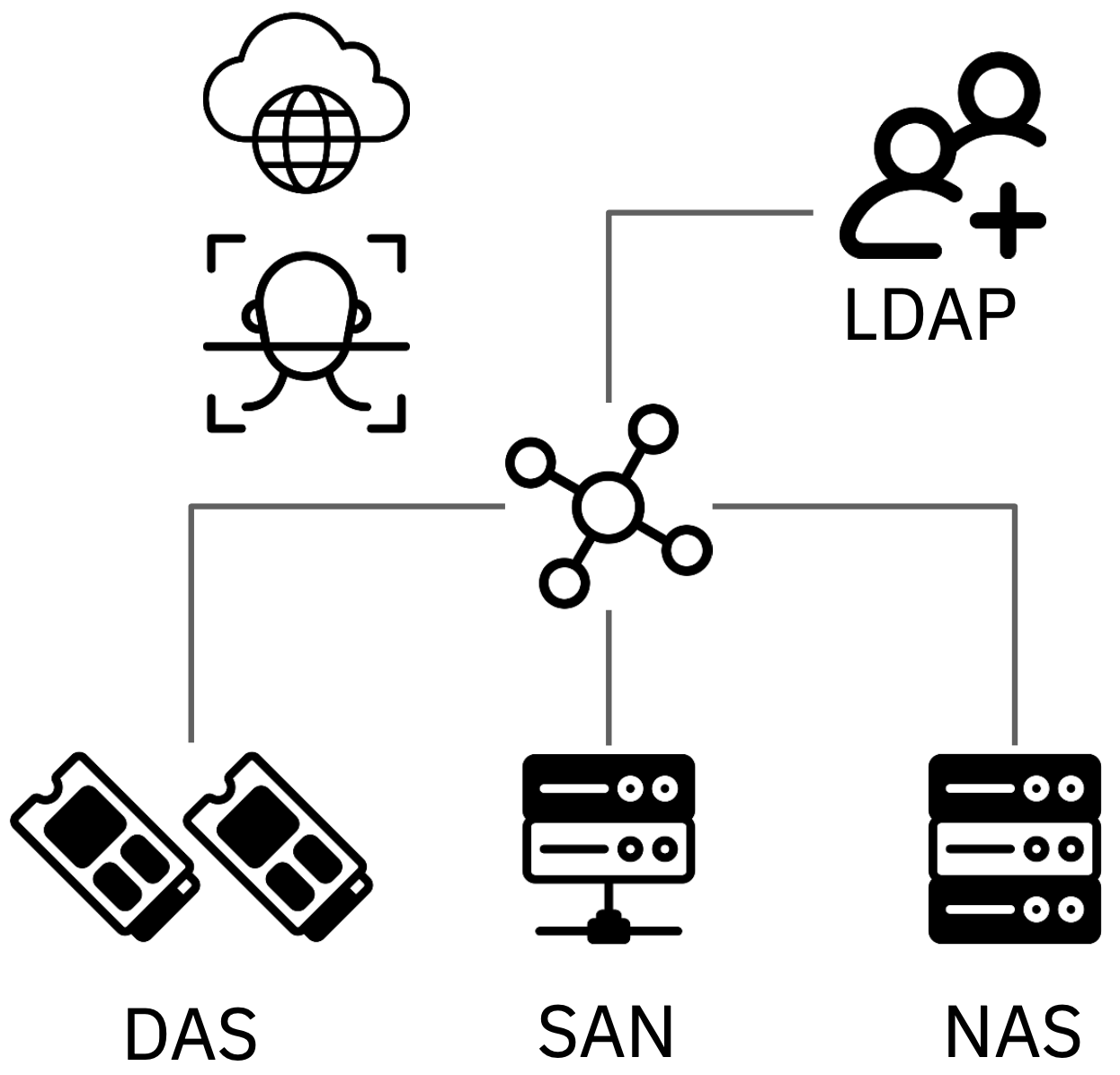
Présentation 1 : Bases du Stockage Réseau - Quand le Stockage Devient une Fonction Réseau
Ce premier support de cours pose les bases du stockage moderne et explique comment cette fonction est passée d'un système local à un service réseau à part entière.
Trois objectifs essentiels :
- Maîtriser les familles de stockage : comprendre les trois modes d'accès fondamentaux (bloc, fichier et objet), ainsi que les technologies associées (DAS, SAN et NAS), du SCSI traditionnel aux solutions NVMe les plus récentes.
- Gérer les volumes logiques : développer une compétence en matière d'abstraction du stockage physique avec les solutions LVM, ZFS et Btrfs, afin d'assurer une flexibilité, une résilience et des performances optimales.
- Évaluer les enjeux d'usage : analyser les critères de choix (capacité, disponibilité, évolutivité) et comprendre l'impact de la virtualisation sur les performances, notamment l'effet « I/O Blender ».
Présentation 2 : Systèmes de Fichiers Réseau et Stockage Objet - L'Art du partage intelligent
Cette deuxième présentation approfondit les mécanismes de partage et d'accès aux données via les réseaux, en se concentrant sur les protocoles NFS et SMB, ainsi que sur les architectures de stockage objet.
Trois objectifs importants :
- Comparer les systèmes de fichiers distribués : décrire les protocoles NFSv4.2 et SMB 3.1.1, ainsi que leurs mécanismes de sécurité avancés (chiffrement AES, authentification Kerberos) et les architectures parallèles comme pNFS.
- Décrire le stockage objet : introduire l'architecture Ceph avec la séparation données/métadonnées, les algorithmes CRUSH de placement intelligent et la réplication distribuée.
- Associer la sécurité et les performances : intégrer le chiffrement en transit et au repos, gérer les topologies backend/frontend et minimiser l'impact de la latence réseau sur l'expérience utilisateur.
Présentation 3 : Gestion Réseau des Identités - Entrer dans l'ère de l'identité numérique
Trois objectifs à mettre en avant :
- Moderniser l'authentification : migrer des méthodes traditionnelles (mots de passe + SMS/TOTP) vers les standards FIDO2 et l'authentification comportementale par IA, en intégrant les protocoles OAuth 2.0 et OpenID Connect.
- Centraliser la gestion des identités : déployer des solutions LDAP et Active Directory avec SSSD pour unifier l'accès aux magasins d'identités hétérogènes et assurer la continuité de service en mode déconnecté.
- Découvrir la gestion des identités et des accès natifs au cloud : présenter le cloud-native IAM avec fédération d'identités, tokens JWT et conformité réglementaire (RGPD, NIS2) intégrée dès la conception.
La compréhension approfondie des briques fonctionnelles du stockage réseau et de la gestion d'identité s'impose aujourd'hui comme une compétence stratégique pour les futurs ingénieurs. Disposer d'une vision claire et précise de ces mécanismes permet non seulement de consolider les bases techniques, mais aussi de gagner en autonomie dans le choix, le déploiement et l'administration d'infrastructures critiques. Cette démarche est d'autant plus cruciale dans une perspective d'émancipation numérique, où l'ambition de bâtir des solutions de cloud souverain – libres des dépendances vis-à-vis des géants du secteur – devient un enjeu majeur pour assurer la résilience, la sécurité et l'indépendance technologique des organisations.