L'objectif de développement étant l'initiation, on se limite à un code minimaliste utilisant deux programmes distincts : un serveur ou listener et un client ou talker. Ces deux programmes échangent des chaînes caractères. Le client émet un message que le serveur traite et retransmet vers le client. Le traitement est tout aussi minimaliste ; il convertit la chaîne de caractères reçue en majuscules.
Le schéma ci-dessous permet de faire la correspondance entre les couches de la modélisation contemporaine et celles de la représentation macroscopique d'un système d'exploitation.
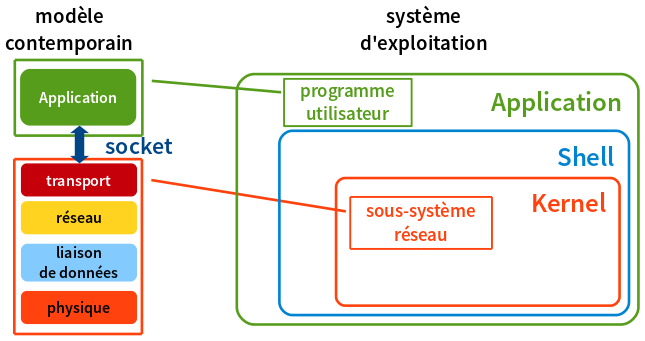
Le logiciel correspondant aux protocoles allant de la couche physique jusqu'à la couche transport fait partie du sous-système réseau du noyau du système d'exploitation.
Le programme utilisateur est lancé à partir de la couche Shell et est exécuté au niveau application.
L'utilisation de sockets revient à ouvrir un canal de communication entre la couche application et la couche transport. La programmation des sockets se fait à l'aide de bibliothèques standard présentées ci-après : Section 2.4, « Bibliothèques utilisées ».
Il est possible de compiler les deux programmes client et serveur en l'état sur n'importe quel système GNU/Linux. Il suffit d'appeler le compilateur C de la chaîne de développement GNU en désignant le nom du programme exécutable avec l'option -o.
$gcc -Wall -Wextra -o udp-talker.o udp-talker.c$gcc -Wall -Wextra -o udp-listener.o udp-listener.c$ls udp* udp-listener.c udp-listener.o udp-talker.c udp-talker.o
L'évaluation des deux programmes client et serveur est assez simple. On peut les exécuter sur le même hôte dans deux Shells distincts en utilisant l'interface de boucle locale pour les communications réseau.
- Le programme serveur, udp-listener.o
-
$./udp-listener.o Entrez le numéro de port utilisé en écoute (entre 1500 et 65000) : 4500 Attente de requête sur le port 4500 >> depuis 127.0.0.1:39311 Message reçu : texte avec tabulation et espaces - Le programme client, udp-talker.o
-
$./udp-talker.o Entrez le nom du serveur ou son adresse IP : 127.0.0.1 Entrez le numéro de port du serveur : 4500 Entrez quelques caractères au clavier. Le serveur les modifiera et les renverra. Pour sortir, entrez une ligne avec le caractère '.' uniquement. Si une ligne dépasse 100 caractères, seuls les 100 premiers caractères seront utilisés. Saisie du message : texte avec tabulation et espaces Message traité : TEXTE AVEC TABULATION ET ESPACES Saisie du message : .
Lorsque le programme serveur est en cours d'exécution, il est possible de visualiser la correspondance entre le processus en cours d'exécution et le numéro de port en écoute à l'aide de la commande netstat.
$ netstat -aup | grep -e Proto -e udp-listener
(Tous les processus ne peuvent être identifiés, les infos sur les processus
non possédés ne seront pas affichées, vous devez être root pour les voir toutes.)
Proto Recv-Q Send-Q Adresse locale Adresse distante Etat PID/Program name
udp 0 0 *:4500 *:* 3157/udp-listener.oDans l'exemple ci-dessus, le numéro de port 4500 apparaît dans la colonne Adresse locale et processus numéro 3157 correspond bien au programme udp-listener.o dans la colonne PID/Program name.
Les deux programmes utilisent les mêmes fonctions disponibles à partir des bibliothèques standards.
-
libc6-dev,netdb.h -
Opérations sur les bases de données réseau. Ici, ce sont les fonctions
getaddrinfo()etgai_strerror()qui sont utilisées. La première fonction manipule des enregistrements de typeaddrinfoqui contiennent tous les attributs de description d'un hôte réseau et de la prise réseau à ouvrir. Parmi ces attributs, on trouve la famille d'adresse réseau IPv4 ou IPv6, le type de service qui désigne le protocole de couche transport TCP ou UDP et l'adresse de l'hôte à contacter. Pour obtenir plus d'informations, il faut consulter les pages de manuels des fonctions :man getaddrinfopar exemple. -
libc6-dev,netinet/in.h -
Famille du protocole Internet. Ici, plusieurs fonctions sont utilisées à partir du paramètre de description de socket
sockaddr_in. Les quatre fonctions importantes traitent de la conversion des nombres représentés suivant le format hôte (octet le moins significatif en premier sur processeur Intel) ou suivant le format défini dans les en-têtes réseau (octet le plus significatif en premier). Ici le format hôte fait référence à l'architecture du processeur utilisé. Cette architecture est dite «petit-boutiste» pour les processeurs de marque Intel™ majoritairement utilisés dans les ordinateurs de type PC. À l'inverse, le format défini dans les en-têtes réseau est dit «gros-boutiste». Cette définition appelée Network Byte Order provient à la fois du protocole IP et de la couche liaison du modèle OSI.-
htonl()ethtons(): conversion d'un entier long et d'un entier court depuis la représentation hôte (octet le moins significatif en premier ou Least Significant Byte First) vers la représentation réseau standard (octet le plus significatif en premier ou Most Significant Byte First). -
ntohl()etntohs(): fonctions opposées aux précédentes. Conversion de la représentation réseau vers la représentation hôte.
-
-
libstdc++6-dev,stdio.h -
Opérations sur les flux d'entrées/sorties de base tels que l'écran et le clavier. Ici, toutes les opérations de saisie de nom d'hôte, d'adresse IP, de numéro de port ou de texte sont gérées à l'aide des fonctions usuelles du langage C.
Les fonctions d'affichage sans formatage
puts()etfputs()ainsi que la fonction d'affichage avec formatageprintf()sont utilisées de façon classique.En revanche, la saisie des chaînes de caractères à l'aide de la fonction
scanf()est plus singulière. Comme le but des communications réseau évaluées ici est d'échanger des chaînes de caractères, il est nécessaire de transmettre ou recevoir des suites de caractères comprenant aussi bien des espaces que des tabulations.La syntaxe usuelle de saisie d'une chaîne de caractère est :
scanf("%s", msg);Si on se contente de cette syntaxe par défaut, la chaîne saisie est transmise par le programme client mot par mot. En conséquence, le traitement par le programme serveur est aussi effectué mot par mot.
Pour transmettre une chaîne complète, on utilise une syntaxe du type suivant :
scanf(" %[^\n]%*c", msg);Le caractère espace situé entre les guillemets de gauche et le signe pourcentage a pour but d'éliminer les caractères
' ','\t'et'\n'qui subsisteraient dans la mémoire tampon du flux d'entrée standardstdinavant la saisie de nouveaux caractères.La syntaxe
[^\n]précise que tous les caractères différents du saut de ligne sont admis dans la saisie. On évite ainsi que les caractères' 'et'\t'soient considérés comme délimiteurs.L'ajout de
%*cpermet d'éliminer le délimiteur'\n'et tout caractère situé après dans la mémoire tampon du flux d'entrée standard.Enfin, pour éviter tout débordement de la mémoire tampon du même flux d'entrée standard, on limite le nombre maximum des caractères saisis à la quantité de mémoire réservée pour stocker la chaîne de caractères. La «constante»
MAX_MSGdéfinie via une directive de préprocesseur est introduite dans la syntaxe de formatage de la saisie. Pour cette manipulation, on fait appel à une fonction macro qui renvoie la valeur deMAX_MSGcomme nombre maximum de caractères à saisir.On obtient donc finalement le formatage de la saisie d'une chaîne de caractères suivant :
scanf(" %"xstr(MAX_MSG)"[^\n]%*c", msg);
D'une manière générale, toutes les fonctions sont documentées à l'aide des pages de manuels Unix classiques. Soit on entre directement à la console une commande du type : man inet_ntoa, soit on utilise l'aide du gestionnaire graphique pour accéder aux mêmes informations en saisissant une URL du type suivant à partir du gestionnaire de fichiers : man:/inet_ntoa.
Au dessus du protocole de couche réseau IP, on doit choisir entre deux protocoles de couche transport : TCP ou UDP.
Dans l'ordre chronologique, le protocole TCP est le premier protocole à avoir été développé. Il «porte la moitié» de la philosophie du modèle Internet. Cette philosophie veut que la couche transport soit le lieu de la fiabilisation des communications. Ce protocole fonctionne donc en mode connecté et contient tout les outils nécessaires à l'établissement, au maintien et à la libération de connexion. De plus, des numéros de séquences garantissent l'intégrité de la transmission et le fenêtrage de ces numéros de séquences assure un contrôle de flux. Tout ces mécanismes ne sont pas évidents à appréhender pour un public débutant.
Le protocole UDP a été développé après TCP. La philosophie de ce mode de transport suppose que le réseau de communication est intrinsèquement fiable et qu'il n'est pas nécessaire de garantir l'intégrité des transmissions et de contrôler les flux. On dit que le protocole UDP n'est pas orienté connexion ; ce qui a pour conséquence d'alléger considérablement les mécanismes de transport.
L'objectif du présent document étant d'initier à l'utilisation des sockets, on s'appuie dans un premier temps sur le protocole de transport le plus simple : UDP. Les programmes client ou talker et serveur ou listener sont repris dans un second temps en utilisant le protocole TCP. En termes de développement, les différences de mise en œuvre des sockets sont minimes. C'est à l'analyse réseau que la différence se fait sachant que les mécanismes de fonctionnement des deux protocoles sont très différents.
Pour plus d'informations, consulter le support Modélisations réseau.
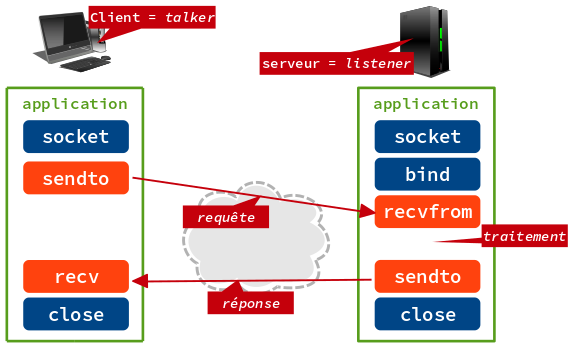
Le schéma ci-dessous présente les sous-programmes sélectionnés côté client et côté serveur pour la mise en œuvre des sockets avec le protocole de transport UDP.
Les appels de sous-programmes avec les passages de paramètres sont détaillés dans les sections suivantes.
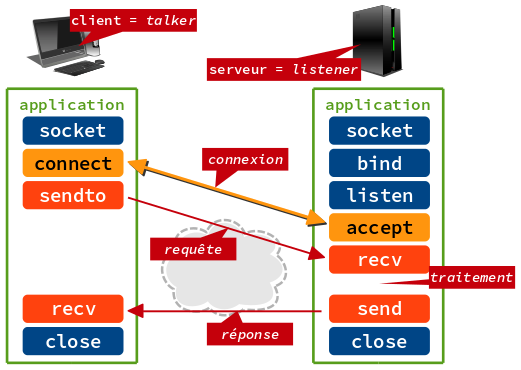
Le schéma ci-dessous présente les sous-programmes sélectionnés côté client et côté serveur pour la mise en œuvre des sockets avec le protocole de transport TCP.
Les appels de sous-programmes avec les passages de paramètres sont détaillés dans les sections suivantes.