Pour aborder la tolérance aux pannes réseau sur les deux liens qui relient l'aire OSPF au routeur de niveau supérieur ISP, on reprend très exactement la configuration de la section précédente avec répartition du trafic sur ces deux mêmes liens.
Toujours comme dans le cas de la section précédente sur la répartition de trafic, la tolérance aux pannes sur les passerelles de l'aire OSPF est assurée par le protocole de routage dynamique. En effet, OSPF étant un protocole à état de liens, l'ajout ou le retrait d'un lien entraîne un nouveau calcul de la topologie par chacun des routeurs de l'aire. On a vu précédemment, que les deux passerelles de l'aire OSPF sont publiées par R1 et R3. Les états des deux liens entre l'aire et le routeur ISP sont donc intégrés dans les calculs de topologie.
Une fois encore, sans configuration particulière le routeur ISP ne dispose pas de fonctionnalité permettant de faire évoluer sa table de routage en fonction de l'état des liens sur lesquels il est directement connecté.
On se propose de compenser cette lacune en plusieurs étapes.
-
Au lieu de modifier une unique table de routage statique, on va créer plusieurs tables de routage que l'on utilisera suivant le lien d'arrivée du trafic sur le routeur
ISP. -
Pour identifier le trafic issu d'un lien, on va marquer ce trafic de façon à ce que le trafic retour emprunte le même lien. Le point clé ici étant que le routeur
ISPne peut pas recevoir de trafic via un lien inactif.
Avec la distribution Debian GNU/Linux, le paquet iproute fournit les outils nécessaires aux manipulations sur les tables de routages multiples.
-
On commence par éditer le fichier
/etc/iproute2/rt_tablesqui permet de faire la correspondance entre l'identifiant numérique de table et le nom que l'on souhaite lui donner. Ici, on choisit de numéroter les deux tables de routage supplémentaires avec les numéros des VLANs de chacun des liens de raccordement de l'aire OSPF au routeurISP.$cat /etc/iproute2/rt_tables # # reserved values # 255 local 254 main 253 default 0 unspec # # local # 101 link101 103 link103 -
Une fois les deux tables de routage supplémentaires disponibles, on saisit la route de synthèse (static summary route) dans chacune.
#ip route add 10.1.0.0/19 via 10.1.30.1 src 10.1.30.2 table link101#ip route add 10.1.0.0/19 via 10.1.30.9 src 10.1.30.10 table link103Du point de vue configuration système, ces deux instructions sont placées dans le fichier de configuration des interfaces réseau du routeur
ISP. -
On définit ensuite les conditions dans lesquelles ces tables de routage seront utilisées.
#ip rule add fwmark 101 table link101#ip rule add fwmark 103 table link103Ainsi, tout paquet IP portant la marque
101sera routé via la tablelink101. Il en ira de même avec la marque103et la tablelink103.
Dans les fonctions réseau du noyau Linux on parle de routage avancé dès que l'on ne se contente plus de l'examen de l'adresse IP destination des paquets reçus sur une interface réseau. L'utilisation d'un marquage des paquets pour orienter le routage entre bien dans cette catégorie.
Les fonctions de routage avancé utilisent une base de données de politiques de routage ou Routing Policy DataBase (RPDB). En utilisant cette base, il est possible de prendre une décision d'acheminement des paquets sur les différents champs des en-têtes de paquet IP, les protocoles réseau, les protocoles de transports et même la charge utile des paquets. Dans notre cas, c'est le marquage des paquets qui permet d'identifier les liens par lesquels ils ont transité. Ce marquage est contrôlé par les outils de filtrage réseau du noyau Linux : netfilter/iptables.
On distingue deux parties dans les outils de filtrage réseau du noyau Linux. La partie noyau, baptisée netfilter, comprend l'ensemble des fonctions disponibles ainsi que le découpage en tables et en chaînes. Ces fonctions sont appelées et utilisées à l'aide de la partie utilisateur baptisée iptables. Généralement, la partie utilisateur est fournie avec un paquet du même nom. Pour plus de détails sur l'organisation et la configuration du système de filtrage, consulter le guide Tutoriel iptables.
Dans le cas de cet article, le marquage des paquets utilise la notion d'altération de paquet ou packet mangling.
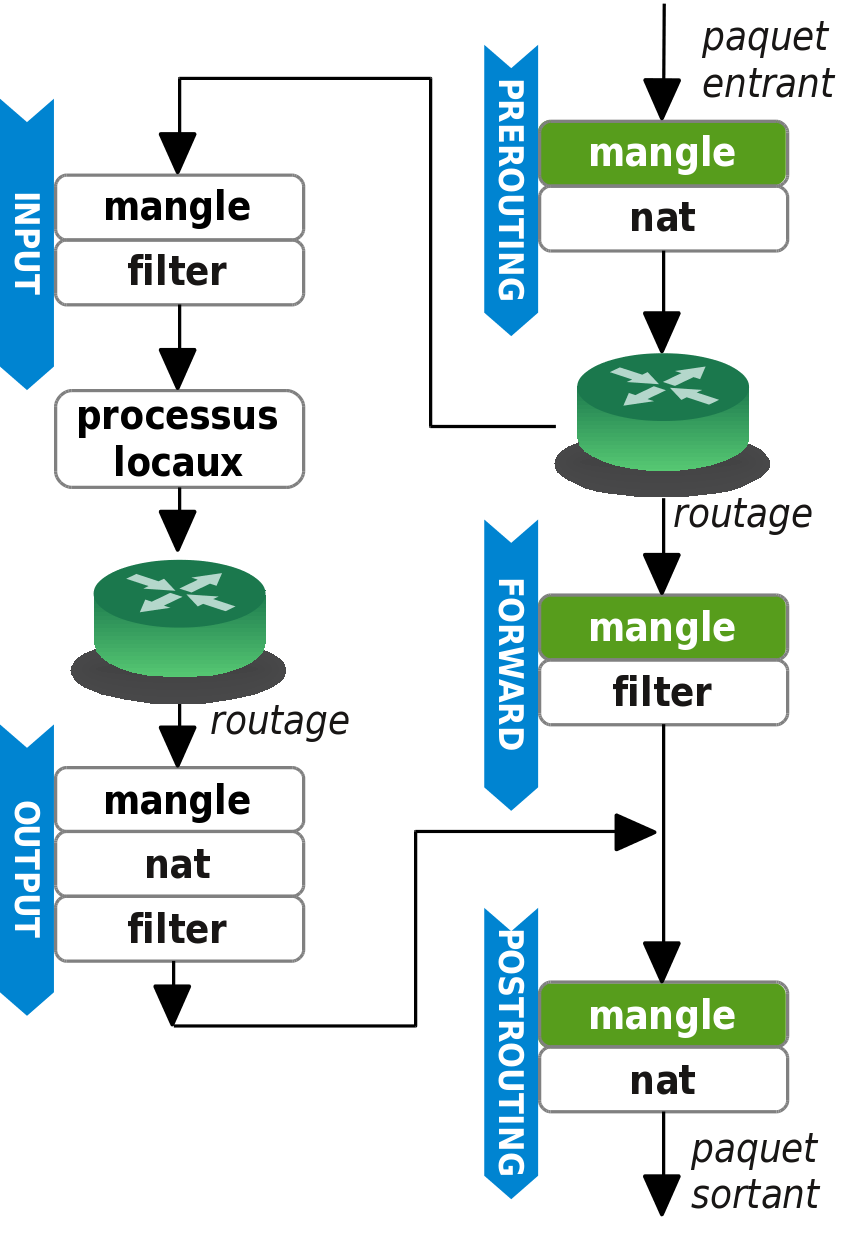 Comme le trafic émis et reçu par l'hôte
Comme le trafic émis et reçu par l'hôte host ne fait que transiter par le routeur ISP, on s'intéresse plus particulièrement à la chaîne PREROUTING de la table mangle. Les processus locaux du routeur ne sont donc pas concernés par le marquage.
![[Avertissement]](/images/warning.png) |
Avertissement |
|---|---|
|
Le propos de cette section est le marquage et non le filtrage des paquets routés par |
Une fois que la table et la chaîne sont choisies, il faut définir la correspondance à utiliser. C'est à ce niveau qu'intervient une fonction très intéressante : CONNMARK. Cette correspondance permet d'associer le marquage des paquets au mécanisme de suivi des communications réseau. Ainsi, un flux entrant dans le routeur ISP via les interfaces de connexion à l'aire OSPF (eth1.101 ou eth1.103) est marqué et enregistré dans la table de suivi des communications. La marque peut alors être restituée à l'arrivée du flux retour sur l'interface externe (eth0). Les instructions correspondant aux choix effectués sont les suivantes.
-
Marquage des flux sortants de l'aire OSPF.
#iptables -t mangle -A PREROUTING -i eth1.101 -j MARK --set-mark 0x65#iptables -t mangle -A PREROUTING -i eth1.103 -j MARK --set-mark 0x67#iptables -t mangle -A PREROUTING -i eth1.101 -j CONNMARK --save-mark#iptables -t mangle -A PREROUTING -i eth1.103 -j CONNMARK --save-mark -
Restauration du marquage des flux retours à destination de l'aire OSPF.
#iptables -t mangle -A PREROUTING -i eth0 -j CONNMARK --restore-mark
Du point de vue configuration système, les règles appliquées à l'aide de la commande iptables peuvent être enregistrées dans un fichier de configuration et restaurées à chaque initialisation du routeur. Voir Annexe D, Configuration du filtrage réseau.
Le fonctionnement du marquage peut être caractérisé à plusieurs niveaux. En reprenant l'exemple de la consultation de pages web depuis l'hôte host et en consultant les résultats du marquage des paquets, on obtient les informations suivantes.
- Consultation de la base FIB, Commutation de paquets IP
-
On retrouve les informations de marquage au niveau réseau dans la Forwarding Information Base. La base FIB est une table de hachage contenant une trace l'ensemble des décisions de routage. La taille de la base augmente rapidement avec le nombre des flux réseau routés par
ISP. C'est la raison pour laquelle on ne donne pas une copie complète de cette base ci-dessous.L'instruction de consultation de la base FIB est la suivante.
$ip route ls cacheDeux exemples d'entrées portant la marque
101ou0x65.192.0.32.8 from 10.1.20.2 via 192.0.2.1 dev eth0 src 10.1.30.2 mark 0x65 cache iif eth1.101 10.1.20.2 from 192.0.32.8 via 10.1.30.1 dev eth1.101 src 192.0.2.3 mark 0x65 cache ipid 0x0be6 rtt 7ms rttvar 6ms cwnd 10 iif eth0La première ligne correspond à la décision d'acheminement des paquets émis par
host(10.1.20.2) à destination de l'adresse192.0.32.8reçus sur l'interfaceeth1.101. La seconde ligne correspond à la décision symétrique.Deux exemples d'entrées portant la marque
103ou0x67.192.0.32.9 from 10.1.20.2 via 192.0.2.1 dev eth0 src 10.1.30.2 mark 0x67 cache iif eth1.103 10.1.20.2 from 192.0.32.9 via 10.1.30.9 dev eth1.103 src 192.0.2.3 mark 0x67 cache ipid 0x0be6 rtt 7ms rttvar 6ms cwnd 10 iif eth0Comme dans le cas des deux entrées précédentes, la première ligne correspond à la décision d'acheminement des paquets émis par
host(10.1.20.2) à destination de l'adresse192.0.32.9reçus sur l'interfaceeth1.103et la seconde ligne correspond à la décision symétrique. - Consultation de la base conntrack, Table de suivi des communications
-
Les mêmes informations de marquage se retrouvent au niveau de la table de suivi des communications réseau. Pour consulter les entrées de cette table, on peut utiliser l'outil conntrack fourni avec le paquet du même nom. Là encore, le nombre des entrées augmente rapidement avec l'apparition de nouveaux flux réseau.
L'instruction de consultation de la table de suivi des communications réseau est la suivante.
#conntrack -LDeux exemples d'entrées portant la marque
101.tcp 6 68 TIME_WAIT src=10.1.20.2 dst=192.0.32.8 sport=37926 dport=80 src=192.0.32.8 dst=10.1.20.2 \ sport=80 dport=37926 [ASSURED] mark=101 use=1 tcp 6 81 TIME_WAIT src=10.1.20.2 dst=192.0.32.8 sport=37927 dport=80 src=192.0.32.8 dst=10.1.20.2 \ sport=80 dport=37927 [ASSURED] mark=101 use=1Un autre exemple d'entrée portant la marque
103.tcp 6 92 TIME_WAIT src=10.1.20.2 dst=192.0.32.9 sport=56108 dport=80 src=192.0.32.9 dst=10.1.20.2 \ sport=80 dport=56108 [ASSURED] mark=103 use=1La table
conntrackfait apparaître les conditions d'identification d'un flux retour en identifiant en plus du protocole de couche transport les paires d'adresses IP en communication ainsi que les paires de numéros de ports utilisés.
Maintenant que les fonctions de marquage des paquets sont en place, les liens actifs entre l'aire OSPF et le routeur de niveau supérieur sont identifiés. Il reste à qualifier la tolérance aux pannes à l'aide de l'analyse réseau.
Pour caractériser la tolérance aux pannes sur les liens réseau entre l'aire OSPF et le routeur ISP, on procède de la façon suivante.
-
On lance la capture de trafic dans un terminal dédié sur le routeur
ISP. -
On lance le téléchargement d'un image iso de DVD dans un terminal dédié sur l'hôte
host. L'idée est d'effectuer les interruptions de liens pendant qu'une transaction réseau est en cours. -
De retour sur
ISP, on identifie le lien utilisé pour le téléchargement à l'aide de la commande conntrack. C'est ce lien que l'on doit interrompre en premier de façon à provoquer le basculement d'un lien vers l'autre en cas de panne. -
Partant du routeur
ISP, on se connecte surR3puisR1pour faire «tomber» le lien correspondant au VLAN et à la marque101. On rétablit ensuite ce même lien. -
Partant du routeur
ISP, on se connecte surR1puisR3pour faire «tomber» le lien correspondant au VLAN et à la marque103. On rétablit ensuite ce même lien. -
On retourne sur l'hôte
hostpour constater que le téléchargement est toujours en cours et se poursuit normalement. Ce téléchargement peut maintenant être arrêté. -
On arrête la capture de trafic sur
ISPet récupère le fichier d'enregistrement des paquets capturés pour l'analyser.
Voici une trace des commandes exécutées sur les différents routeurs et sur l'hôte à l'initiative du trafic.
-
Sur le routeur
ISP, la capture de trafic est le point important.$screen tshark -i eth1 ! port 22 -w /var/tmp/failover-host.pcap -
Sur l'hôte
host, on lance le téléchargement «long».$screen wget http://cdimage.debian.org/debian-cd/6.0.3/amd64/iso-dvd/debian-6.0.3-amd64-DVD-1.iso -
Sur le routeur
R1, on désactive puis réactive le lien versISP.#ifconfig eth0.101 down <attendre un certain temps.../>#ifconfig eth0.101 up#ip ro add default via 10.1.30.2 -
De même, sur le routeur
R3, on désactive puis réactive le lien versISP.#ifconfig eth0.103 down <attendre un certain temps.../>#ifconfig eth0.103 up#ip ro add default via 10.1.30.10
À la différence de la section Section 4.2, « Analyse réseau sur le routeur ISP avec répartition de trafic », le volume de trafic capturé est beaucoup plus important. On ne propose donc ici qu'une représentation graphique caractérisant le basculement d'un lien sur l'autre à chaque désactivation d'interface.
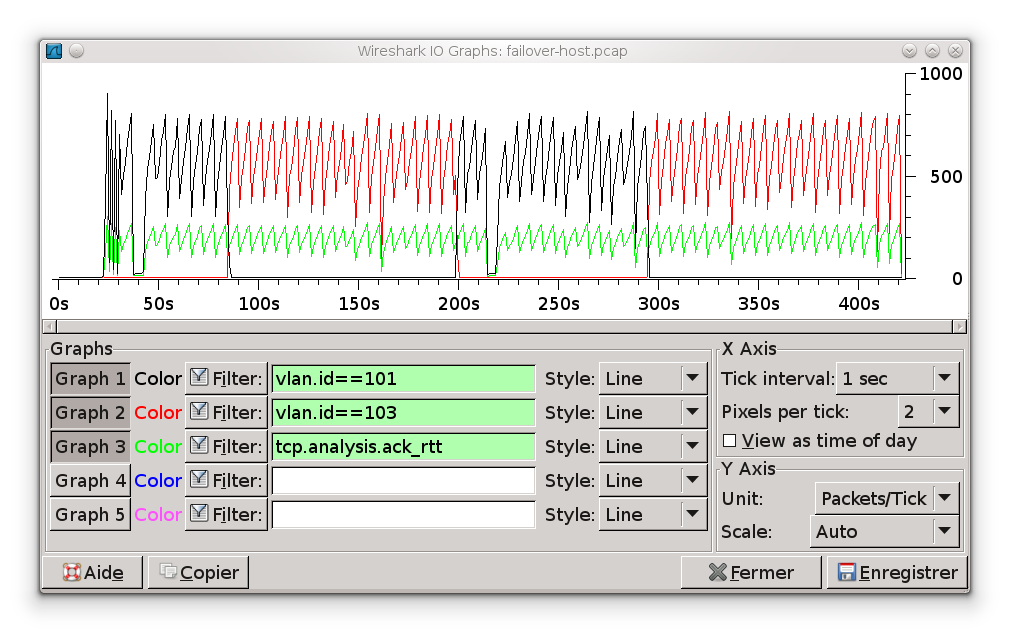
Il y aurait beaucoup de remarques à faire sur cette capture de téléchargement. Simplement :
-
La courbe noire correspond à l'utilisation du lien entre
R1etISP: le VLAN101. -
La courbe rouge correspond à l'utilisation du lien entre
R3etISP: le VLAN103. -
La courbe verte est là pour indiquer que certains délais observés lors des échanges sont dus à la communication de bout en bout entre l'hôte
hostet le serveur web et non au système de tolérance aux pannes réseau.