Dans l'histoire des systèmes Unix, les services de nommage ont connu de nombreuses évolutions avec le développement de l'Internet et des volumes d'informations à partager.
Au début des années 80, un premier service baptisé Network Information Service (NIS) a vu le jour. Ce service est une méthode de distribution de la base de données des utilisateurs, de fichiers de configuration, d'authentification et d'autres données entre les hôtes d'un réseau local. Le logiciel NIS développé par Sun Microsystems™ fonctionne sur le mode Client/Serveur à partir d'une base de données «à plat» (flat bindery base). Son utilisation est étudiée dans le support de travaux pratiques Introduction au service NIS. Avec un service NIS, il n'est pas possible de constituer des groupes logiques ayant des attributs propres. Cette limitation est rapidement devenue critique avec l'augmentation du nombres des utilisateurs et des clients.
D'autres services plus complets tels que NIS+ ou kerberos qui n'assure que la partie authentification ont été développés par la suite. Depuis quelques années, les annuaires LDAP ou Lightweight Directory Access Protocol se sont imposés comme étant l'outil d'échange universel des paramètres utilisateurs.
Pour définir ce qu'est le service LDAP, on peut retenir les caractéristiques suivantes.
-
Un service de publication d'annuaire
-
Un protocole d'accès aux annuaires de type X.500 ou Lightweight Directory Access Protocol
-
Un dépôt de données basées sur des attributs ou un «genre» de base de données
-
Un logiciel optimisé pour les recherches avancées et les lectures
-
Une implémentation client/serveur
-
Un mécanisme extensible de schémas de description de classes d'objets
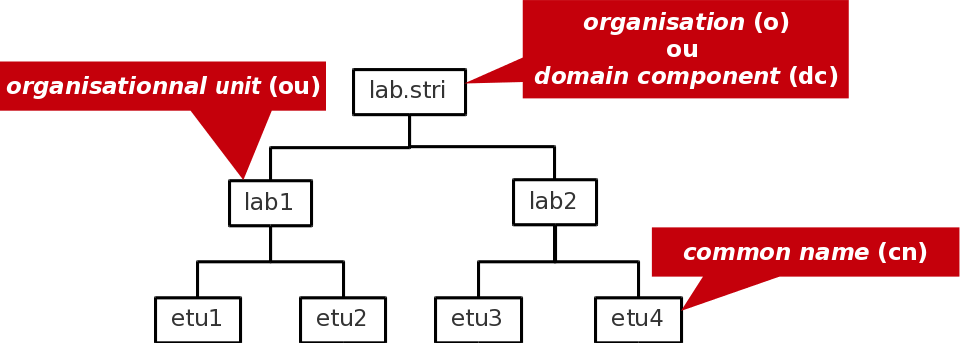
Les entrées (Directory Service Entry) d'un annuaire LDAP sont distribuées suivant une arborescence (Directory Information Tree) hiérarchisée que l'on peut voir comme un système de fichiers avec ses répertoires et ses fichiers. Au sommet de l'arborescence on trouve un nom de racine (Domain Component) ou suffixe.
{kind=link}
L'adresse d'une entrée de l'annuaire LDAP est appelée : distinguished name ou dn. En reprenant l'exemple d'arborescence ci-dessus, les adresses des différentes entrées sont notées comme suit.
-
dn: dc=lab,dc=stri -
dn: ou=lab1,dc=lab,dc=stridn: ou=lab2,dc=lab,dc=stri -
dn: cn=etu1,ou=lab1,dc=lab,dc=stridn: cn=etu2,ou=lab1,dc=lab,dc=stridn: cn=etu3,ou=lab2,dc=lab,dc=stridn: cn=etu4,ou=lab2,dc=lab,dc=stri
L'adresse de chaque entrée appartient à une classe d'objet (ObjectClass) spécifiée dans un schéma (schema). En reprenant les mêmes exemples d'entrées, on peut associer les classes d'objets correspondantes.
| entry | objectclass |
|---|---|
|
|
|
|
|
|
|
|
|
Un schéma peut être vu comme un ensemble de règles qui décrivent la nature des données stockées. C'est un outil qui aide à maintenir la cohérence, la qualité et qui évite la duplication des données dans l'annuaire. Les attributs des classes d'objets déterminent les règles qui doivent être appliquées à une entrée. Un schéma contient les éléments suivants.
-
Les attributs requis
-
Les attributs autorisés
-
Les règles de comparaison des attributs
-
Les valeurs limites qu'un attribut peut recevoir
-
Les restrictions sur les informations qui peuvent être enregistrées