Résumé
|
Ce support de travaux pratiques aborde la mise en œuvre d'un annuaire LDAP avec le logiciel OpenLDAP. Il décrit l'installation et la configuration du démon |
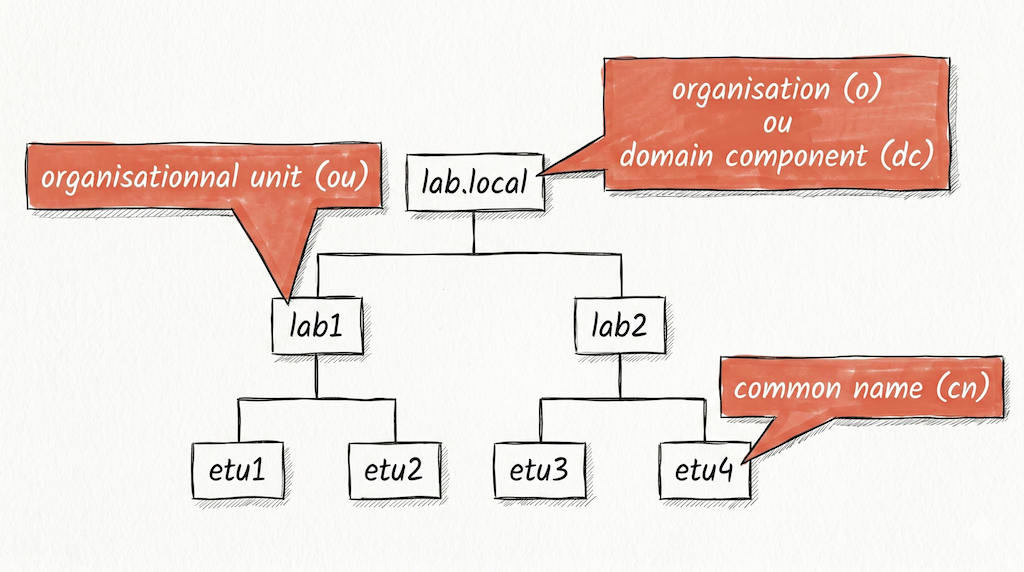 |
Table des matières
- 1. Objectifs
- 2. Topologie, scénario et plan d'adressage
- 3. Principes d'un annuaire LDAP
- 4. Installer et configurer le serveur LDAP
- 5. Composer un nouvel annuaire LDAP
- 6. Configurer l'accès client au serveur LDAP
- 7. Sécuriser les échanges entre clients et serveur LDAP
- 8. Accéder à l'annuaire LDAP depuis un service Web
- 9. Conclusion
- 10. Documents de référence
Après avoir réalisé les manipulations proposées dans ce support, vous serez en mesure de :
- Décrire les principes d’un annuaire LDAP
-
Comprendre la notion d’arbre d’information ou de Directory Information Tree (DIT), la composition d’une entrée à partir de classes d’objets et de schémas, le format d’échange LDIF et les opérations d’interrogation et de modification de la base.
- Configurer un service d’annuaire OpenLDAP
-
Installer le démon
slapd, analyser sa configuration dynamique stockée dans le DITcn=config, réinitialiser la base de l’annuaire pour adopter un nouveau contexte de nommage et y composer une arborescence de comptes utilisateurs à l’aide de fichiers LDIF. - Configurer un système client avec un accès transparent à l’annuaire
-
Mettre en œuvre le mécanisme Name Service Switch en s’appuyant sur les paquets
libnss-ldapdetlibpam-ldapdafin que les comptes utilisateurs publiés dans l’annuaire soient utilisables comme s’ils étaient déclarés localement, et valider l'authentification via PAM. - Sécuriser l’authentification et les échanges avec Kerberos et TLS
-
Mettre en place un royaume Kerberos local, créer le principal de service de l’annuaire, configurer l’authentification SASL/GSSAPI, puis déployer une autorité de certification locale afin d’activer StartTLS sur le port
389/tcpet le serviceldaps://sur le port636/tcp. - Exposer l’annuaire à travers un service Web
-
Installer et paramétrer le service White Pages du projet LDAP Tool Box afin de publier un trombinoscope des comptes de l’annuaire, en exploitant notamment l’attribut
jpegPhoto.