Des services de nommage Unix aux annuaires LDAP
Dans l'histoire des systèmes Unix, les services de nommage ont connu de nombreuses évolutions au rythme du développement de l'Internet et de la croissance des volumes d'informations à partager entre hôtes.
Au début des années 80, un premier service baptisé Network Information Service (NIS) a vu le jour. Développé par Sun Microsystems™, ce service met en œuvre une méthode de distribution de la base de données des utilisateurs, des fichiers de configuration, d'authentification et d'autres données entre les hôtes d'un réseau local. Il fonctionne sur le mode client/serveur à partir d'une base de données « à plat » (flat bindery base). Avec NIS, il n'est pas possible de constituer des groupes logiques dotés d'attributs propres. Cette limitation est rapidement devenue critique avec l'augmentation du nombre d'utilisateurs et de clients.
Depuis de nombreuses années, les annuaires LDAP (Lightweight Directory Access Protocol) se sont imposés comme l'outil d'échange universel des paramètres utilisateurs. Ils s'appuient sur le modèle X.500 hérité des télécommunications, mais débarrassé du protocole de transport OSI au profit de TCP/IP.
Caractéristiques du service LDAP
Pour définir ce qu'est le service LDAP, on peut retenir les caractéristiques suivantes :
-
Un service de publication d'annuaire.
-
Un protocole d'accès aux annuaires de type X.500, le Lightweight Directory Access Protocol.
-
Un dépôt de données fondé sur des attributs typés, à mi-chemin entre une base de données et un système de fichiers hiérarchique.
-
Un logiciel optimisé pour les recherches avancées et les opérations de lecture fréquentes, au détriment des écritures.
-
Une implémentation client/serveur normalisée par l'IETF (RFC 4510 et suivantes).
-
Un mécanisme extensible de schémas pour la description des classes d'objets et de leurs attributs.
-
Un format d'échange textuel standardisé, le LDIF (LDAP Data Interchange Format, RFC 2849), qui permet l'export, l'import et la sauvegarde des entrées.
Arborescence et nommage des entrées
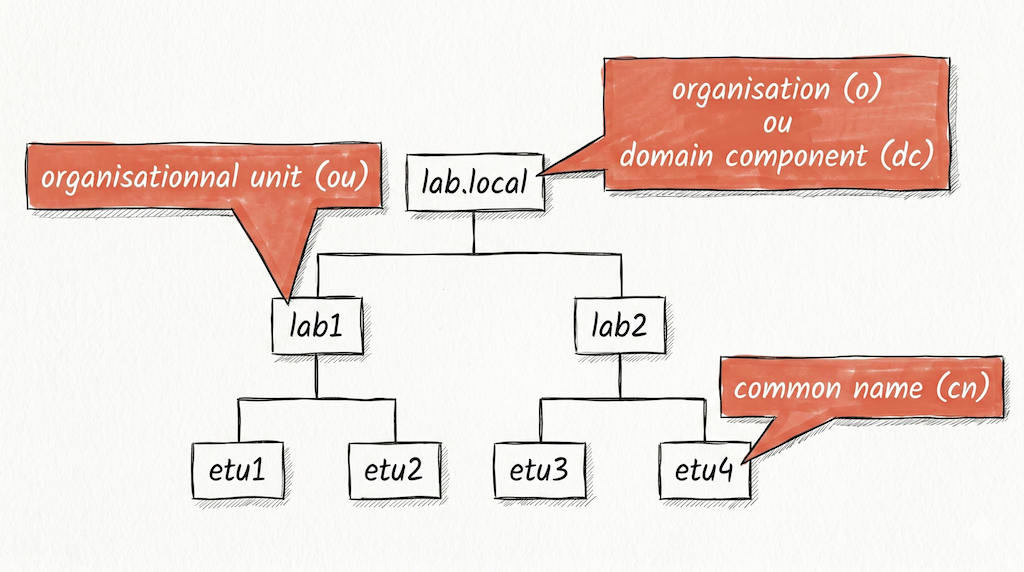
Les entrées (Directory Service Entry) d'un annuaire LDAP sont distribuées suivant une arborescence hiérarchisée, le Directory Information Tree (DIT), que l'on peut comparer à un système de fichiers avec ses répertoires et ses fichiers. Au sommet de l'arborescence se trouve un suffixe ou contexte de nommage, généralement exprimé sous forme de Domain Component (dc=) calqué sur le nom DNS de l'organisation.
{kind=link}
L'adresse d'une entrée de l'annuaire LDAP est appelée distinguished name (DN). Elle est construite par concaténation, de la feuille vers la racine, des relative distinguished names (RDN) rencontrés sur le chemin. En reprenant l'exemple d'arborescence ci-dessus, les adresses des différentes entrées s'écrivent ainsi :
-
dn: dc=lab,dc=local -
dn: ou=lab1,dc=lab,dc=localdn: ou=lab2,dc=lab,dc=local -
dn: cn=etu1,ou=lab1,dc=lab,dc=localdn: cn=etu2,ou=lab1,dc=lab,dc=localdn: cn=etu3,ou=lab2,dc=lab,dc=localdn: cn=etu4,ou=lab2,dc=lab,dc=local
![[Note]](/images/note.png) |
Note sur la cohérence des noms. |
|---|---|
|
Le contexte de nommage |
Classes d'objets et schémas
Chaque entrée appartient à une ou plusieurs classes d'objets (objectClass) spécifiées dans un schéma (schema). En reprenant les mêmes exemples d'entrées, on peut associer les classes d'objets correspondantes :
Tableau 3. Exemple de correspondances entre objets et classes
| entry | objectclass |
|---|---|
|
|
|
|
|
|
|
|
|
Un schéma peut être vu comme un ensemble de règles qui décrivent la nature des données stockées. C'est l'outil qui aide à maintenir la cohérence et la qualité des informations et qui évite la duplication des données dans l'annuaire. Les attributs des classes d'objets déterminent les règles à appliquer à chaque entrée. Un schéma comporte typiquement les éléments suivants :
-
Les attributs requis (MUST).
-
Les attributs autorisés (MAY).
-
Les règles de comparaison (matching rules) appliquées aux attributs.
-
Les types de syntaxe et les valeurs limites qu'un attribut peut recevoir.
-
Les restrictions sur les informations qui peuvent être enregistrées.
Avec OpenLDAP, ces schémas sont chargés dynamiquement dans le sous-arbre de configuration cn=schema,cn=config, ce qui permet d'ajouter ou de mettre à jour des classes d'objets sans redémarrer le démon slapd.
Opérations protocolaires
Le protocole LDAP définit un ensemble d'opérations standardisées que tout client peut envoyer au serveur. On retient principalement :
- Bind / Unbind
-
Ouverture et fermeture d'une session authentifiée. Le bind peut être anonyme, simple (DN + mot de passe) ou s'appuyer sur le cadre SASL pour déléguer l'authentification à un mécanisme externe (GSSAPI/Kerberos, EXTERNAL via certificat client, etc.).
- Search
-
Interrogation de l'annuaire à partir d'une base de recherche, d'une portée (`base`, `one`, `sub`) et d'un filtre conforme à la RFC 4515.
- Compare
-
Vérification de la valeur d'un attribut sans révéler son contenu.
- Add / Delete / Modify / Modify DN
-
Opérations de modification de la base, généralement appliquées à partir de fichiers LDIF.
- Extended operations
-
Opérations négociées, dont la plus représentative est
StartTLSqui permet d'élever une connexion en clair sur le port389/tcpvers une session chiffrée TLS, en alternative au serviceldaps://historique sur le port636/tcp.
Format LDIF
Toutes les manipulations sur les objets de l’annuaire utilisent un format de fichier texte particulier baptisé LDIF pour LDAP Data Interchange Format. Chaque enregistrement est séparé du suivant par une ligne vide et chaque attribut apparaît sur une ligne sous la forme nomAttribut: valeur.
Rôle de la structuration des annuaires LDAP dans la gestion d'identité moderne
Au-delà de leur rôle historique, les annuaires LDAP sont actuellement considérés comme des composants essentiels dans la gestion des identités et des accès (IAM, Identity and Access Management) au sein des systèmes d'information contemporains. La qualité de la structuration du DIT, déterminée par le choix du contexte de nommage, le découpage en unités organisationnelles, les conventions de RDN et la sélection des classes d'objets, influe directement sur la pérennité, la sécurité et l'interopérabilité des services qui y sont raccordés.
Ce rôle central s'explique par plusieurs facteurs :
- Source de vérité unique
-
Un annuaire correctement structuré tient lieu de référentiel commun pour les comptes Unix (via NSS/PAM), les sessions Kerberos, les portails web (OpenID Connect ou CAS qui interrogent LDAP en arrière-plan), les outils collaboratifs (Mattermost, Zulip, GitLab, Nextcloud) ou encore les équipements réseau (TACACS+/RADIUS adossés à LDAP).
- Délégation d'administration
-
La hiérarchie en « organizational units » permet d'accorder des droits d'écriture limités à des administrateurs métier (
ou=people,ou=groups,ou=services,ou=hosts), sans compromettre la racine. Les ACL (Access Control List) d'OpenLDAP s'appuient de manière explicite sur la position de l'entrée dans l'arborescence. - Cycle de vie des identités
-
Une structuration claire facilite l'automatisation de l'embarquement (onboarding) et du départ (offboarding) des utilisateurs au moyen d'outils d'infrastructure-as-code (Ansible, Salt) ou de provisionnement standard (SCIM 2.0, RFC 7644), qui consomment et produisent du LDIF ou des opérations LDAP idempotentes.
- Sécurité et auditabilité
-
Le couplage avec Kerberos (une authentification forte sans transmission de mot de passe) et avec TLS (confidentialité et intégrité des échanges, validation mutuelle par certificats X.509) repose sur la cohérence entre noms DNS, principals Kerberos et DN LDAP. Une structure rigoureuse garantit l'exploitabilité des traces et l'application uniforme des politiques de mot de passe (policydata).
- Conformité et gouvernance
-
Dans le cadre du RGPD, des référentiels ANSSI et des normes ISO/IEC 27001, il est impératif de pouvoir lister, qualifier et restreindre les accès aux données personnelles. Un DIT bien structuré, accompagné de schémas pertinents, facilite la cartographie des attributs sensibles et la mise en œuvre de la minimisation des données.
- Évolutivité et fédération
-
Dans le contexte d'un système d'information contemporain, les annuaires LDAP sont intégrés dans des architectures de fédération d'identités (Keycloak, FreeIPA, 389 Directory Server, Samba AD, OpenBAO pour les secrets associés). Afin d'assurer la capacité d'exportation, de réplication (
syncrepl) ou d'exposition d'un sous-arbre via des passerelles, il est impératif de procéder à une structuration préalable.
Autrement dit, un annuaire LDAP ne se limite pas à un simple dépôt de comptes. Cette infrastructure transversale doit être conçue comme un projet à part entière dès sa phase de développement. Les décisions stratégiques prises en matière de nommage, de classification des objets (inetOrgPerson, posixAccount, posixGroup, groupOfNames, krbPrincipalAux) et de profondeur de l'arborescence auront un impact durable sur l'évolution du système d'information.
Les parties suivantes de ce document illustrent ces principes dans le contexte du nommage dc=lab,dc=local de manière très modeste.